Budgets, Budgets Everywhere!
Happy New Year! I’m very excited to announce the beta release of Buckets v0.73.0 which includes two major features:
- Budgets from different devices can now be merged together
- You can now share budgets using a shared network folder
Buckets is one step closer to working seamlessly on mobile!

A few important caveats¶
If you’d like to give this a try, there are some things to be aware of:
- Once you open a budget with this new beta version, you will not be able to open it with an older version of Buckets. Make a backup of your budget!
- This beta release is incompatible with the current iOS and Android versions. We’re hoping to get compatible mobile versions out soon, but they’re not ready yet.
- We’ve tested a lot but there might be some bugs. Again, make a backup of your budget :)
If you didn’t read above¶
Make a backup copy of your budget.
So what does it look like?¶
The Sharing preference pane has a new Avenue type called “Shared folder.” Select the same shared folder on both devices (via Google Drive, Dropbox, iCloud, Syncthing or whatever else you use to sync files) and your devices will eventually see each other and let you share between them. Here’s what it looks like on Alice’s computer who’s sharing with Bobby:
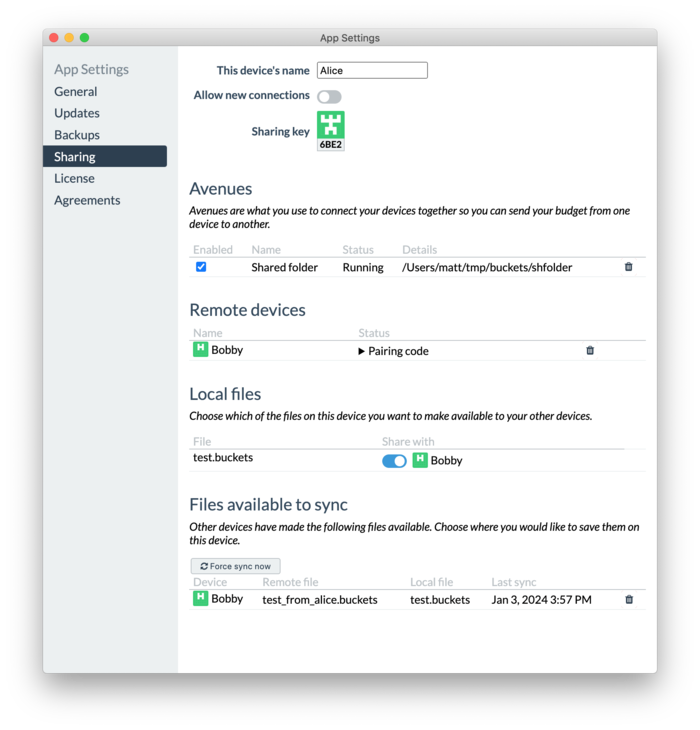
See the Guide included with the release (Help > Guide > Sharing) for particulars.
Once both devices are using the same folder, whenever a device sees an update, you’ll get a notification badge on the Tools sidebar menu directing you to the new Merge Budgets tool:
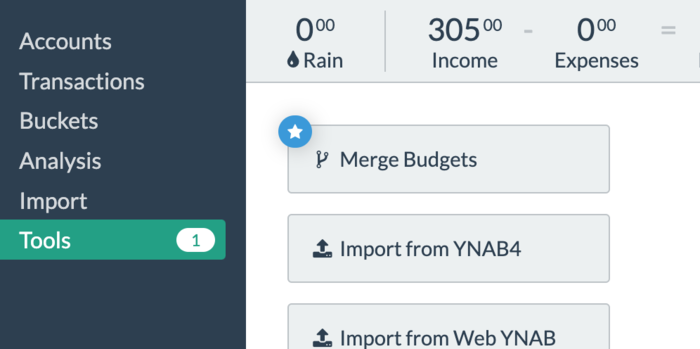
For now merging will be manually triggered so that it’s easier to tell what’s going on. But once real world testing reveals the problems we missed, we’ll gradually make things more automatic.
And it’s all encrypted by default¶
To maintain your privacy, all data is encrypted before saving it in shared folders. And you don’t even have to pick a password!
If you’re up for giving it a try (and want your budget on multiple computers), download the latest beta here.
Happy Budgeting!
Technical details¶
If you’re interested in all the nitty gritty technical details, keep reading—implementing this has been a very challenging and fun programming problem.
Tracking changes¶
I started working on the ability to merge budget files sometime in 2018 and posted about a way to track changes with JSON in SQLite. I’ve nearly released different versions of change-tracking since then, but wasn’t satisfied with how they worked. For an evolving program like Buckets, change tracking needs to be fast, small, flexible and resilient.
My first idea was to just start tracking every change and figure out merging later. Essentially, there was a table like this:
> select * from changelog;
id created action obj data
-- ------------------- ------ ------ ------------------------------------
1 2024-01-04 02:54:30 INSERT bucket {"id":5,"name":"Food","color":"red"}
2 2024-01-04 02:54:52 UPDATE bucket {"id":5,"name":"Groceries"}
3 2024-01-04 02:55:03 UPDATE bucket {"id":5,"color":"green"}
I’m really glad this wasn’t released. It isn’t small since every piece of data is duplicated at least twice. Also, since Buckets is very INSERT heavy and much more light on UPDATEs and DELETEs, I really wanted a solution that avoided tracking INSERTs.
So, as described in the JSON SQLite blog post I got something working that only tracked UPDATEs and DELETEs. Again I nearly released it, but tried to implement merging just to see what it was like. While simple merging worked, it exposed a big problem: ID reconciliation among independent devices using sequential integer IDs is very difficult.
For instance, if Alice adds a new bucket to her budget, she’ll take the next ID (say 5). But if Bob adds a new bucket to his budget before merging in Alice’s changes, his bucket’s ID will be 5 as well. When it comes time to merge those budgets, it’s possible but very annoying and error-prone to keep track of whose 5 is who’s and then update one of the 5’s to 6 in the end.
CRDT¶
I should pause here, since some of you are yelling at your computer, to mention that I’ve read about conflict-free replicated data types (CRDTs), and while I’m open to the possibility of one day using CRDTs in Buckets, it’s not the right tool for now since it would require too much restructuring of the budget format and because it might be more rigid than I want (read on).
Back to sequential IDs and their problems…
GUIDs¶
After thinking through and partially implementing many ideas for doing merging while keeping sequential numeric IDs (because SQLite makes them so easy), including:
- Adding a random hash column to every table
- Identifying records by both their ID and their timestamp
- Adding a device ID column to every table
I bit the bullet and just switched the numeric ID over to a proper GUID. Sort of. 😁
Initially, I wanted to save space so desperately that I tried to pack all the GUID information into a 64-bit integer. There was a timestamp portion, a sequential portion and a random portion all consuming what I thought were just enough bits to avoid collisions. Here is one version of that:
const
ID_SIZE = 53 # 53 because JavaScript can't handle 64-bit integers
ID_TS_SIZE = 31 # 31 bits will allow for 68 years before wrap-around
ID_RANDOM_SIZE = 16
ID_SEQ_SIZE = ID_SIZE - ID_TS_SIZE - ID_RANDOM_SIZE
UUID_TS_SHIFT* = ID_SEQ_SIZE + ID_RANDOM_SIZE
UUID_TS_MOD* = 2 ^ ID_TS_SIZE
UUID_SEQ_SHIFT* = ID_RANDOM_SIZE
UUID_SEQ_MOD* = 2 ^ ID_SEQ_SIZE
UUID_RANDOM_MOD* = 2 ^ ID_RANDOM_SIZE
const
uuiddef = (&"""(
((CAST(strftime('%s', 'now') AS INT) % {UUID_TS_MOD}) << {UUID_TS_SHIFT})
+ ((last_insert_rowid() % {UUID_SEQ_MOD}) << {UUID_SEQ_SHIFT})
+ (abs(random()) % {UUID_RANDOM_MOD})
)""").replace("\n", "")
uuidprimarykey* = &"INT PRIMARY KEY DEFAULT {uuiddef}"
But you’ll notice that’s not a 64-bit number because JavaScript’s Number.MAX_SAFE_INTEGER is only 53 bits. The hours it took to realize this were very painful.
At this point, trying to decide between always converting a 64-bit integer to a string for JavaScript or using a 53-bit integer was made easier when my testing revealed that the 53-bit UUID ran into collisions. Rather than deal with converting IDs between strings and integers (though SQLite is very friendly about situations like this), I opted to just go with strings.
So now IDs in Buckets are strings with a big timestamp in front (ordering by ID is still useful) and a big chunk of random at the end:
SELECT ( printf('%x', julianday('now')*86400000) || '-' || lower(hex(randomblob(10))) );
c15510e0dc0d-b2bfa93a683e4ded298e
It has increased the size of our budget a bit, but it’s an acceptable amount.
Schema changes¶
After switching to GUIDs, merging became much simpler. I was again almost ready to release, but paused to work on another feature that required a database schema change. As I made the change, it hit me that once the changelog became active, I would have to duplicate the same schema change within the data contained in the changelog.
For instance, if the notes column were removed from the account table, we’d need to remove the notes key from anywhere it appeared within the JSON list of changed columns. Maintaining these schema changes in the changelog is possible and some applications might decide to do this…
But at this point, after having worked on change tracking and merging for so long, I took a step back and realized: it doesn’t need to be perfect—it only needs to be good enough 99% of the time and resilient enough that it can be fixed the other 1%. And I don’t want to apply schema changes to history if I can help it!
So here’s how a change log looks in the beta release:
> select obj, obj_id, action from change_log;
obj obj_id action
------------------- --------------------------------- ------
bucket c1550f6ce47a-9078a1c0a72495cd6d0c U
bucket c1550f6ce5b3-93c8713f4166b73593c8 U
bucket c1550f62cf7c-faa7603c46a24e98b405 U
account c1550f5d8c76-ffe9072c4b2f6c65b12a U
account c1550bc23e3b-7b97d5248c833320ecc2 U
account c1550bc08d49-0cfff4e2a0e74e2597b9 U
bucket c15510e0dc0d-b2bfa93a683e4ded298e D
account_transaction c15510e0dc0d-a24e9a3a67d5248d298e U
Only the fact that an UPDATE or DELETE happened is tracked. INSERTs are determined by computing the difference of each database. And the set of fields that changed by an UPDATE are also determined by comparing the two databases.
This is small and very flexible in the face of schema changes.
Conflicts¶
Fixing conflicts is left up to users, because in most Buckets usage (lots of INSERTs and typically only one device doing stuff at a time), conflicts should be rare rather than common. But when conflicts do arise, here’s how they’re resolved within the Merge Budgets tool:
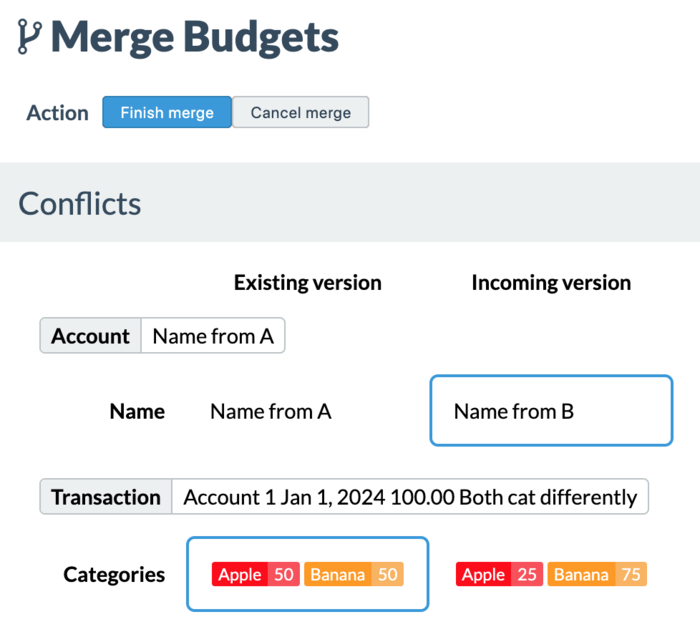
For each conflict click on either the existing version or the incoming version before completing the merge. The above image shows that an account was renamed differently on each device and a transaction was split differently between the Apple and Banana buckets.
Merging two databases¶
SQLite is great software. Merging two budgets involves attaching the incoming budget to the destination budget, querying across both databases to determine differences, copying changes over and then detaching.
At one point, my goal was to make The Ultimate SQLite Database Merging Algorithm™ that could merge any database you could throw at it. But I eventually calmed down and the merging algorithm is more bespoke for Buckets, much simpler and more accurate.
Shared folder format¶
The new Shared folder avenue is another satisfying piece of work. Here’s an example of the directory structure. When you get it working on your computer, feel free to poke around and look at these files.
sharedfolder/
├── buckets.share.txt
└── devices
├── 868664ED40D4C8E238F154110EB49F1F
│ ├── device.json
│ └── device.json.hash
└── A0F2D74B5644C91F87F436EDCB40C34C
├── budgets
│ └── 1
│ ├── budget-20240103232703-683528.gz.enc
│ ├── info.json
│ └── info.json.sig
├── device.json
└── device.json.hash
Each device gets its own directory under devices/$DEVICE_ID where its public signing key and signed public encryption key are published. Any number of devices can use the same shared folder.
Before you can share with another device, the same manual trust verification is done as for the other sharing avenues. It’s hopefully very difficult to accidentally share a budget with someone.
Each device will publish budgets for other devices within its own budgets/$BUDGET_ID directory. Each budget is compressed and encrypted with a symmetric key. That symmetric key is then encrypted with each destination device’s public encryption key and stored in info.json. By doing it this way, each budget only needs to be encrypted and stored once, but is readable by multiple devices.
To avoid a race condition if one device is reading a budget while a new version is being uploaded, the prior version of the budget is retained alongside the newest version, with info.json being updated only after the new budget is in place.
Testing¶
Automated testing for all these changes has been essential. Of the hundreds of tests, many are handcrafted but others are generated by assembling scenarios from a list of possible actions. Writing tests in Nim, with its macro/template system is very satisfying.
This tests updating an account name in both budgets and having one budget ignore the other’s changes:
test "UU discard UU take":
let t = tester()
t.setup: a.insert("account", "a1", {"name": "0"})
t.go:
a.update("account", "a1", {"name": "a1"})
b.update("account", "a1", {"name": "b1"})
a.discardIncoming(b)
a.update("account", "a1", {"name": "a2"})
b.update("account", "a1", {"name": "b2"})
b.takeIncoming(a)
check a.has("account", {"name": "a2"})
check b.has("account", {"name": "a2"})
I’m very excited for this long-time-coming change. After we get the mobile apps to be compatible with these changes, you’ll be able to categorize transactions on mobile!
Happy Budgeting v2!
— Matt
Comments



